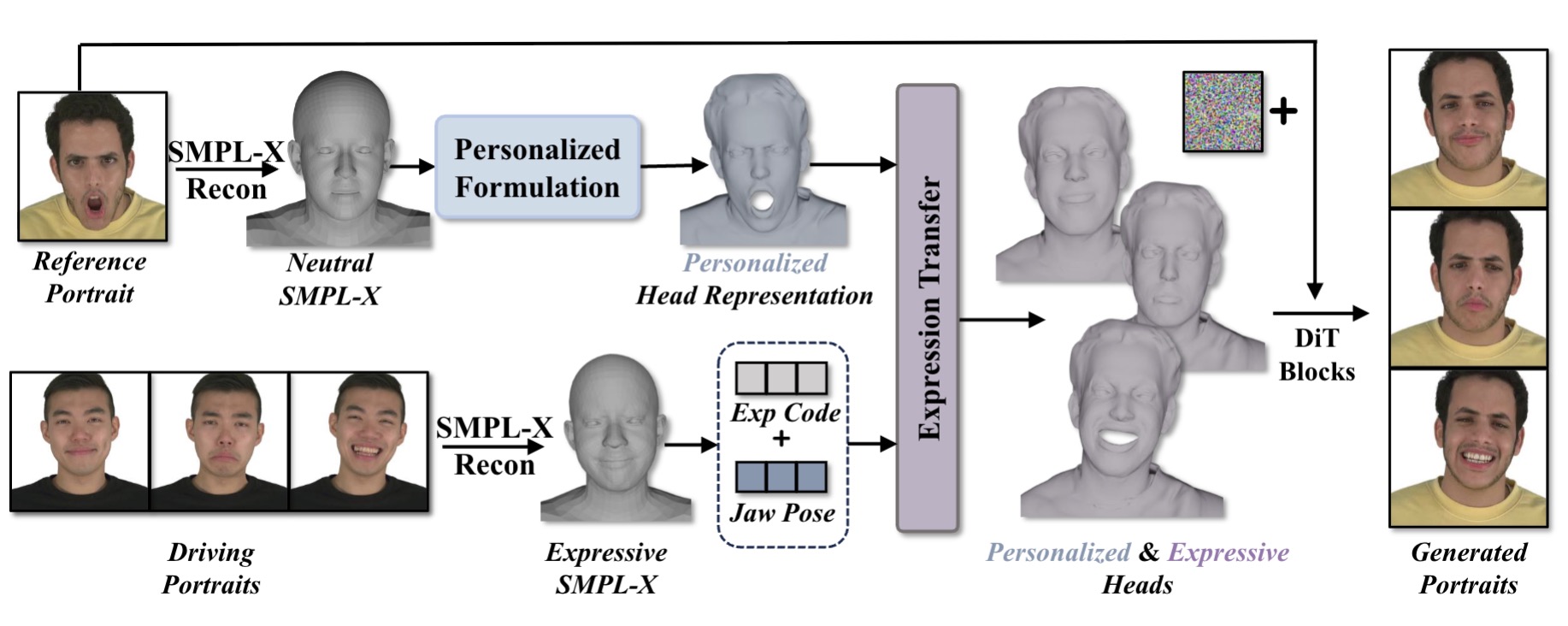
While diffusion models have shown great potential in portrait generation, generating expressive, coherent, and controllable cinematic portrait videos remains a significant challenge. Existing intermediate signals for portrait generation, such as 2D landmarks and parametric models, have limited disentanglement capabilities and cannot express personalized details due to their sparse or low-rank representation. Therefore, existing methods based on these models struggle to accurately preserve subject identity and expressions, hindering the generation of highly expressive portrait videos.
To overcome these limitations, we propose a high-fidelity personalized head representation that more effectively disentangles expression and identity. This representation captures both static, subject-specific global geometry and dynamic, expression-related details. Furthermore, we introduce an expression transfer module to achieve personalized transfer of head pose and expression details between different identities.
We use this sophisticated and highly expressive head model as a conditional signal to train a diffusion transformer (DiT)-based generator to synthesize richly detailed portrait videos. Extensive experiments on self- and cross-reenactment tasks demonstrate that our method outperforms previous models in terms of identity preservation, expression accuracy, and temporal stability, particularly in capturing fine-grained details of complex motion.